
Why Apple’s New Mac Minis Are Great, But Not So Great
October 22, 2014Startup SwiftStack Aims to Scale out Data Center Storage
October 27, 2014Data might seem like a no-problem for the regular person. Dropped right into the mobile age, people can retrieve information at the blink of an eye. But you already know that.
What you might not know, is what it takes to store all the data—which is multiplying immeasurably with each passing day. It’s not as simple as just picking a data center and stuffing all the data into servers. Multiple factors must be well-researched beforehand to make sure the data is protected, easy to access, and cost-effective.
The good thing is, however, that there are so many data center spread across Planet Earth, that there are plenty of options when it comes to the geographical location of where to store you data. It’s a good thing, at least, for companies that don’t have very specific information, i.e. sensitive data like healthcare, banks, insurance, and even gaming platforms.
It gets worse for the kinds of data that house Personally Identifiable Information (PII), which includes such sensitive data like social security numbers, credit card information, birth dates, names, and addresses. This type of data is all grouped together as a part of subscription management. You can only imagine what could happen if this type of data was not handled properly (hint: mass pandemonium).
Before we get deeper into these issues, let’s take a trip in the Colocation America time machine to a day before big data. When one storage location was sufficient and everyone made eye contact and could hold a conversation without having to get a Starbucks and take a selfie with said Starbucks. Data back then was so much easier to wrangle and manage that it was kind of like an afterthought. With all that time devoted to not worrying about data, companies were able to innovate and cause even more data, thus leading to the big-data-boom of today.
Speaking of today, many companies work and offer services to all over the world. This, unsurprisingly, has led to governments all over the world standardizing and throwing a fit over data privacy, leading many to govern that PII data should be stored in the originating country. Oh, yay, data is now political—and in typical political fashion, there are regulations that companies must follow when they operate across continents.
Alas, companies can either store data where it’s most convenient (and risk non-compliance) or store this particular kind of data separately per regulations. As you can imagine, this can cause quite a few headaches for businesses who just want a simple and efficient way to store all of their data in one place.
What is the solution?
Nodes. Yes, those nodes. Those nodes that are so ambiguous that they’re just nodes. By these nodes are useful nodes. Nodes what I mean? (I’m sorry about that).
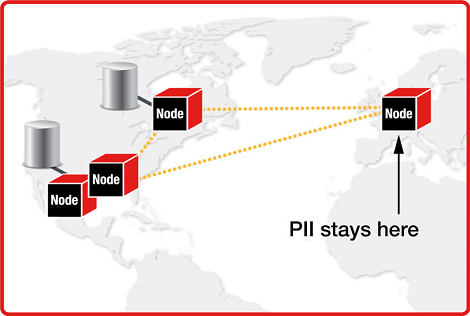
Anyways, companies can run a data integration solution that buddies up with their current data stores. When a transaction happens, it’s stored as regular, with region specific data stored in one of those nodes in the region where the transaction happened.
Say, for instance, that PII data was done in that transaction. Only the PII data will be stored in that node, rather than having a separate instance of the company’s existing data base. Pretty awesome!
The picture above explains it pretty well too.
Go big data!