This Week in Getting Hacked: eChirp Edition
March 16, 2017
This Week in Getting Hacked: You! By Your Congresspeople
March 31, 2017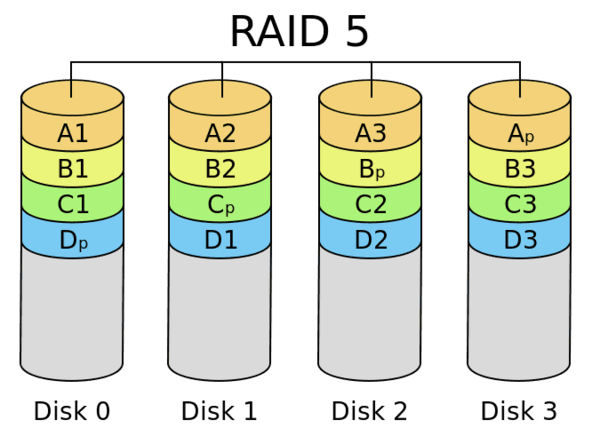
If you’ve spent some time around computers, then you have probably heard the term RAID, even if you had no idea what it meant.
RAID stands for “Redundant Array of Independent Disks.” Yeah, I would use the acronym too. Also, it’s not the bug spray. Just clearing that up.
There are multiple levels of RAID which all do different things, but it all boils down to one thing: data redundancy. Getting you your data faster and/or backing up your data in the case of emergency. https://www.youtube.com/embed/eE7Bfw9lFfs
Now that that’s out of the way, it’s good to know that RAID was invented back in 1988 to combat the costs of the high-performing disk drives back in the day. The argument was that an array of more inexpensive disks can outperform a single expensive disk.
Before we get into the “nitty-gritty,” you can click here to view a list of unfamiliar terminology that could help you understand RAID just a little bit better.
Raid Configurations
RAID 0
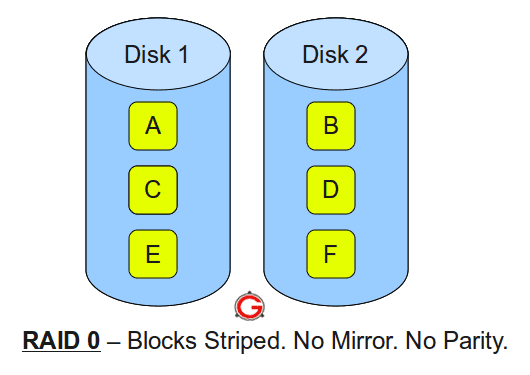
TL;DR: – minimum of two disks – fantastic, striped, performance – no redundancy – not for critical systems
RAID 0 is intended for fast read and write speeds giving the user terrific performance. RAID 0 is a bit different because despite its name, there is no redundancy. Instead, the data is “striped” across the drives which means each disk holds a piece of the overall information.
While this does allow for faster read and write speeds, it also means that if one of the drives fail, there is no way to recover any of the data on any remaining working disks.
RAID 0 is the preferred RAID configuration for gamers, where speed is of the utmost importance.
RAID 1

TL;DR: – minimum two disks – good performance – redundant (through mirrored blocks)
RAID 1 is a setup of at least two drives that contain the exact same data (as seen in the image above). RAID 1 provides what’s called “fault tolerance” meaning when one drive fails, the others will still work.
This is therefore a favorite for those who need high reliability.
The downfall, as you might have guessed, is that it doesn’t offer even close to the same write speeds as a RAID 0 configuration. When data is saved, it must be written to each drive, which, as you might have guessed again, means the write speed can only be as fast as the slowest drive in the array. Subsequently, storage space is also dependent on the smallest drive in the array.
Think of RAID 1’s efficiency as the number of drives divided by the number of drives. Two divided by two is one (one for storage and the other for backup). A five drive configuration still only has one drive’s worth of information (but four backups—talk about redundancy!).
RAID 5
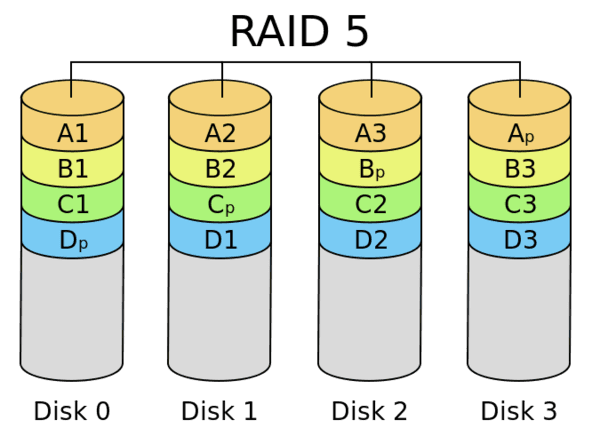
TL:DR: – minimum three disks – good, striped performance – good redundancy (distributed parity) – most cost-effective option for performance and redundancy
The most popular setup, RAID 5 uses a similar striping method as RAID 0, and also has a “parity” distributed across the drives.
Using a logic gate known as Exclusive Or (XOR), data is pieced together in the event of a single drive failure, using the parity information stored on the other drives.
This function runs while the other drives continue their normal operations which means zero downtime in the event of a drive failure. This is why RAID 5 requires at least three drives.
RAID 5 loses 33 percent of storage space (using three drives) for that parity, but it is still a more cost-effective setup than RAID 1. The most popular RAID 5 configurations use four drives, which lowers the lost storage space to 25 percent.
RAID 10
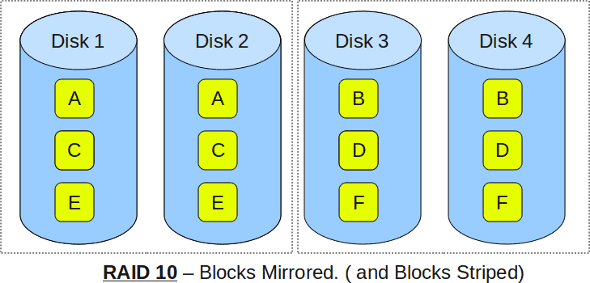
TL:DR: – minimum of four disks – mirrored striping means excellent redundancy and performance – the best option for extremely critical applications (like databases)
RAID 10 consists of a minimum for four drives and has all the advantages of RAID 0 and RAID 1 (albeit at a slightly higher cost).
RAID 10 has the performance characteristics of a RAID 0 configuration, but instead on relying on single disks for striping, a mirrored array is used which provides that all-welcoming redundancy. This means that RAID 10 can provide the speed of RAID 0 with the redundancy of RAID 1, which is why you’ll sometimes see it written as RAID 1+0 (or 10).
How Does RAID Work?
RAID can be created using several different technologies which not only creates them, but manages them.
Hardware RAID
Hardware RAID is dedicated processing system, using controllers or RAID cards to manage the RAID configuration independently from the operating system.
Advantages: Performance and availability.
Since its on its own dedicated hardware, the RAID controller doesn’t take processing power away from the disks it manages. Which means more space and speed can be used to read and write data. Because of that, the RAID managing system should always be ready at bootup making it available more often than not.
Disadvantages: Proprietary and cost.
If the system fails, you’re usually locked into the vendor. Meaning you’ll have to get the exact model again to ensure the RAID system performs according to how you set it up. Thusly, those systems are not cheap, so you’ll have to factor cost into the RAID equation if you go with hardware RAID.
Software RAID
Unlike hardware RAID, software RAID does use the processing power of the operating system in which the RAID disks are installed.
Advantages: Flexible, open-source, cheap.
Since the OS manages nearly everything, you don’t have to reconfigure any hardware. Especially for Linux systems, RAID is open-sourced meaning there’s little divulgence between operating systems. Oh, and open source means that software RAID keeps your costs down .
Disadvantages: performance
Since some processing power is taken by the software, read and write speeds of your RAID configuration can be affected by it. It’s usually minimal, but it is something to consider.
Hardware-Assisted Software RAID
There is a third option called hardware-assisted software RAID which is really just fake RAID. HASR uses a type of firmware on the controller or card within the motherboard to manage RAID, yet uses the CPU to handle most of the processing.
Advantages: Not many.
Really the only advantage to HASR is that RAID is brought up early in the boot process, which may not have been possible with software RAID.
Disadvantages: performance and support.
Much like software RAID, the RAID process must share resources with the rest of the OS. The effects performance, but that’s not the real problem here. HASR really only supports RAID configurations of RAID 0 or RAID 1. The higher classes of RAID aren’t possible with HASR. This is why most try to avoid it, but it can be useful in home media storage or other personal RAID configurations.
Terminology
Below are some common, yet probably unfamiliar terms when dealing with RAID:
- Striping – the process of dividing the disk-writes to the array over multiple underlying disks. This splits the data into “chunks” and each of those “chunks” are are written into at least one of the underlying devices.
- RAID Level – RAID levels refer to the common relationship of the storage devices. Drives can be configured in many ways, leading to different performance and redundancy and they all have a name (RAID 0, RAID 5, etc.).
- Parity – parity is the redundant data that’s recovered from other disks when one drive fails. Parity is distributed across available drives which increases performance and redundancy. In other words, parity is used to reconstruct the data on the array with a drive fails.
Choosing the right RAID configuration for your needs is solely dependent on your business wants and goals. You’ll have to factor in things like redundancy, cost, speed, and reliability, but hopefully this guide can help you along the way. If you have anything to add or have any questions please feel free to comment below.
Note: Most images come from esds