
Friday Fun Blog: Polar Bears Playing Edition
October 7, 2016Friday Fun Blog: Humpback Breach Edition
October 14, 2016
RAID stands for “Redundant Array of Independent Disks” (or, if you’re feeling cheeky, “Redundant Array of Inexpensive Disks”). In a RAID array, multiple hard drives combine to form a single storage volume with no apparent seams or gaps (although, of course, the storage volume can be divided into multiple partitions or iSCSI target volumes as required to suit your needs). Put very simply, RAID is the data storage equivalent of Voltron.
Every hard drive fails eventually (which you learn soon enough if you work for a data recovery lab), and the more hard drives you gather in one place, the more likely you are to have one die on you. Fortunately, RAID fault tolerance helps mitigate this danger and can keep your data safe.
RAID Fault Tolerance and the Threefold Benefits of RAID Arrays
By connecting hard drives together, you can create a storage volume larger than what you could obtain from a single hard drive alone, even today, when you can waltz into a Best Buy or log onto Amazon and get yourself an eight terabyte hard drive that could comfortably hold every episode of Doctor Who and Star Trek (every series, even Enterprise) combined and more.
RAID offers more benefits than just high capacity, of course. Combining several hard drives in a RAID array can have massive improvements in performance as well. The more spindles you have spinning, the more blocks of data you can read from and write to simultaneously, which can dramatically improve the performance of one RAID array versus one single hard drive. RAID performance differs across common RAID levels due to the different ways the various levels function.
RAID offers not only increased storage capacity and improved performance, but also fault tolerance as well. This is why RAID arrays are found most often in the servers of businesses and other organizations of all sizes to run and manage complex systems and store virtual machines for their employees, their email database or SQL database, or other types of data. The three beneficial features of RAID arrays are all interconnected, with each one influencing the other.
RAID fault tolerance is, as its name suggests, the ability for a RAID array to tolerate hard drive failure. This is where the “redundant” part of RAID comes in. RAID fault tolerance gives the array some slack in the case of hard drive failure (which is inevitable and will happen to you sooner or later) by making sure all of the data you put on it has been duplicated so that it can be restored if one or more hard drives fail.
That way, when one disk goes kaput (or more, in the case of some other RAID arrays), you haven’t lost any data. This is great, because the more hard drives you have, the greater chances you have that one of them will kick the bucket. And with RAID fault tolerance, you’ve got an extra cushion making sure your data is safe.
Different arrays have varying degrees of RAID fault tolerance, based on their unique properties, and as we’ll see below, the degree of tolerance also influences the two other benefits RAID arrays have to offer. In general, the more fault tolerant a RAID array is, the less useable capacity and increased performance it has, and vice versa.
RAID Fault Tolerance: RAID-1
One of the simplest RAID arrays is the RAID-1 mirror. RAID-1 arrays only use two drives, which makes them much more useful for home users than for businesses or other organizations (theoretically, you can make a RAID-1 with more than two drives, and although most hardware RAID controllers don’t support such a configuration, some forms of software RAID will allow you to pull it off.)
Whenever you write any kind of data to one drive, the same write command goes to the other drive, making both of them identical twins. This is called a mirrored array because each drive is a perfect mirror of the other. If you lose one hard drive, you’ve lost nothing—You can replace the failed hard drive with a new hard drive to mirror the old one and be none the worse for the wear (besides the cost of replacing the drive).
The effect this RAID level has on drive performance and capacity is fairly obvious. For performance, every write command has to be duplicated. However, when you need to read data from the array, you can read from both drives simultaneously. As for capacity, the RAID-1 array only has one hard drive’s worth of capacity, even if you create a RAID-1 mirror with more than two disks.
RAID-1 tends to be used by home users for simple onsite data backup. This mirrored type of array puts all of its points into redundancy (capacity is its dump stat). The biggest danger to a RAID-1 array is if both drives fail simultaneously, or if one hard drive dies, and then the other dies while the first is being replaced.
A Note on RAID-0: The Zero Tolerance Array
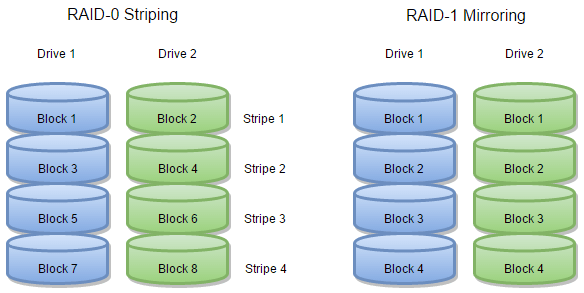
When you combine hard drives in a RAID-0 array, you “stripe” all of the drives together so that all of your data gets broken up into little chunks and written to each drive(usually each block in a stripe stretching across all of the drives in the array is around 64 kilobytes in size). The more hard drives you combine, the more spindles you have spinning at once, and the more simultaneous read and write commands you can pull off, making RAID-0 a high-performance array and the conceptual opposite of RAID-1.
But the performance comes at a cost: There isn’t any room for data redundancy on a RAID-0 array. If you lose one drive, you lose everything—no matter how many hard drives you’ve chained together. There is actually no redundancy to speak of, which is why we hesitate to call RAID-0 a RAID at all. It’s more of an AID (and if you ask me, it’s not much of an “aid” at all—the more drives you have, the greater your chances of one of them failing and taking all of your data with it, and is the performance boost really worth playing with fire considering how much cheaper SSDs are getting?).
RAID-0 may not be a “real” RAID in our eyes, but the way it stripes data carries on through all of the higher RAID levels, so it deserves a mention whenever discussing RAID levels.
RAID Fault Tolerance: RAID-5
RAID-5 has a little trick to take the striping of RAID-0 and add in a sprinkle of fault tolerance. It’s not the first one to add redundancy to a RAID-0-like setup, but all of the RAID levels between RAID-1 and RAID-5 have become obsolete mainly due to the invention of RAID-5, so we can fudge our work a bit and say that RAID-5 is the next step up from RAID-0.
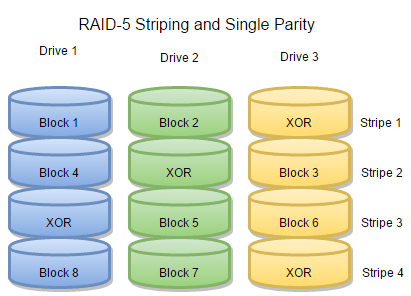
Like RAID-0, RAID-5 breaks all of your data into chunks and stripes them across the hard drives in the array. But it also adds a bit of its special sauce, and this special sauce is XOR parity.
In mathematics, the XOR function, or “exclusive OR” function, allows you to do something that’s actually pretty cool (if you’re a math geek). Let’s say you have a set of three (or any other number of) data blocks. With XOR, you can generate a new block of data based on the originals. Now say one of the original blocks goes missing (if it’s the XOR block, you haven’t lost anything, because the important data still lives in the original values). Here’s the cool part: by performing the XOR function on the remaining blocks, you can figure out what the missing value is!
Here’s a demonstration: Let’s say we have three three-bit blocks of data here. Let’s say these three blocks somehow make up your tax returns (it’s a gross oversimplification, but just for the purposes of demonstration, let’s roll with it).
101 001 100
Now we can perform an XOR calculation on the three blocks. You begin by comparing each bit of two blocks to create a new value. XOR returns a 0 if the values of two bits are all the same and a 1 if they are different. So first we XOR the first two blocks, 101 and 001, producing 100. Then we XOR our new value with the third one. XORing 100 and 100 give us our parity block of 000:
101 001 100 | 000
So how does our three-bit parity blocks help us? Imagine something bad happens to the middle drive and erases the block containing 001:
101 _ 100 | 000
There go all your tax deductions for the year! But don’t start freaking out just yet. We can perform another XOR calculation on the remaining blocks! XOR calculations between 101, 100, and 000 make 001. And there you have it: the missing block. Your data is safe!
This is a (massively simplified) look at how RAID-5 uses the XOR function to reconstruct your data if one hard drive goes missing. Granted, the hard drives in your RAID array are dealing with over 500,000 bits of data in a single block, not three as in this exercise. But, remember, computers are really good at doing lots of math very quickly.
RAID-5 distributes all of its XOR parity data along with the “real” data on your hard drives. In every stripe across the drives in the array, one block stores the parity data for the rest of the blocks. Because no matter how many drives you have, you still only need one parity value for every n blocks, your RAID-5 array has n-1 drives’ worth of storage capacity whether you have three drives or three dozen. It’s a pretty sweet deal—but if you lose another hard drive before you can replace the first drive to fail, you’ll lose your data.
RAID-5 offers performance gains similar to RAID-0 in addition to its capacity and redundancy gains, although these gains are slightly lessened by both the amount of space the parity data takes up and by the amount of computing time and power it takes to do all those XOR calculations. But even so, RAID-5’s cost-effective blend of RAID’s threefold benefits make it one of the most popular RAID levels by far.
RAID Fault Tolerance: RAID-6
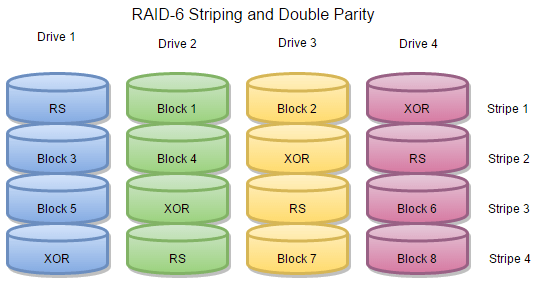
RAID-6 is a tougher and more durable version of RAID-5. Like RAID-5, it uses XOR parity to provide fault tolerance to the tune of one missing hard drive, but RAID-6 has an extra trick up its sleeve. A RAID-6 array has even more parity data to make up for a second hard drive’s failure.
Unfortunately, this extra parity data can’t be explained as easily or neatly as XOR parity. The calculations involve Reed-Solomon error correction codes, which are based on Galois field algebra, and if your head is spinning almost as fast as a hard drive’s platters by now, don’t worry. It’s complicated stuff. If you’re well-enough versed in mathematics, Intel’s white paper on RAID-6 does a good job of illustrating how Galois field algebra applies to RAID-6.
Reed-Solomon error correction codes also see use to correct any sort of data corruption that can naturally occur in any sort of high-bandwidth data transmission, from HD video broadcasts to signals sent to and from space probes. They also reduce read errors in basically any kind of spinning disk media, including CDs, DVDs and Blu-Ray disks, and the disk platters inside your hard drives themselves. They’re also used in QR code and barcode readers so that these codes can be correctly interpreted, even if the reader can’t get a perfect look at them. Reed-Solomon encoding is powerful stuff.
The end result of these two layers of parity data is that a RAID-6 array with n hard drives has n-2 drives’ worth of total capacity, and suffers a slightly larger performance hit than RAID-5 due to the complexity of double parity calculations. However, it also has double the fault tolerance of RAID-5. Up to two hard drives can die on you before your data is in any serious jeopardy.
RAID Fault Tolerance: RAID-10 (RAID 1+0)
No, we didn’t skip RAID levels 7, 8, and 9. The next step up from RAID-6 is RAID-10 (although, honestly, it’s a lateral move in some respects). RAID-10 isn’t the tenth level of RAID array, but rather a combination of RAID-1 and RAID-0.
With RAID-10, you first take your hard drives and match them up into mirrored pairs (therefore, you need an even number of drives). Each hard drive has its own identical twin. On top of that, every mirrored pair gets striped together. The end result is that you have one RAID-0 super-array connecting several RAID-1 mirrored sub-arrays. Or, if it helps to visualize RAID-10 another way, imagine a basic RAID-0 array, except every individual hard drive in the array is actually two twinned drives.
The redundancy benefit of RAID-10 is that you can lose one hard drive from each mirrored sub-array without suffering any data loss. This looks like a lot of fault tolerance, since you can lose half of the hard drives in your array without losing any data or your RAID’s functionality!
But before we get too carried away singing RAID-10’s praises, let’s think about this for a minute. What happens if you lose just two hard drives, but both drives belong to the same RAID-1 sub-array? You get the same result you would if you lost one hard drive from a RAID-0 array: You lose, you get nothing, good day, sir. In this case, RAID-10 would only have just as much fault tolerance as RAID-5—a single drive.
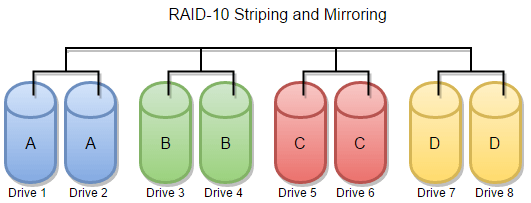
You can make a RAID-10 drive with as little as four drives (two RAID-1 mirrors striped together) or as many hard drives as you can afford. As you increase the number of hard drives, the chances of two drive failures being enough to crash your RAID array decrease from one in three to (given enough hard drives) close to zero. But no matter how many hard drives you put in the array, that possibility will always still exist.
The RAID fault tolerance in a RAID-10 array is very good at best, and at worst is about on par with RAID-5. However, in its defense, RAID-10 does offer much improved performance over RAID-6.
RAID Fault Tolerance: RAID-50 (RAID 5+0)
RAID-50, like RAID-10, combines one RAID level with another. In this case, the two RAID levels are RAID-5 and RAID-0. If you’ve got a handle on RAID-10, it’s easy to visualize RAID-50: simply replace each mirrored pair of drives in a RAID-10 with individual RAID-5 arrays.
Thanks to XOR parity data, every RAID-5 array has one drive’s worth of fault tolerance, as discussed earlier. RAID-50 has just as much variable redundancy as RAID-10: you can lose one hard drive from each sub-array, but if you lose two drives from even one RAID-5 sub-array, you will lose your data.
Because RAID-5 can have, at minimum, three hard drives, and you can only lose one drive from each RAID-5 array, RAID-50 cannot boast about losing half of its hard drives as RAID-10 can. If you make your RAID-5 sub-arrays as small as possible, you can lose at most one-third of the drives in your array. And, as with RAID-10, there is always the danger that two drive failures alone will be enough to take down the entire array.
RAID-50’s benefits over RAID-10 focus more on capacity and performance: Thanks to RAID-5’s parity redundancy, less space is needed to provide roughly the same amount of fault tolerance, and the array’s performance gets a boost from both RAID-5 striping and from RAID-0 striping.
A Note on Other RAID Levels
You may notice that we skipped a few numbers: RAID-2, RAID-3, and RAID-4, in particular. These RAID levels do exist, but no longer see use due to obsolescence. RAID-2 used Hamming error correcting codes instead of XOR or Reed-Solomon parity to provide fault tolerance, while RAID-3 and RAID-4 used XOR parity, but held all of the parity data on a single disk instead of distributing it across the disks as RAID-5 does. In general, RAID-5 does just about everything these arrays do, only better. Therefore those three RAID levels have, more or less, gone the way of the dodo.
There are also nested RAID arrays combining RAID-3, RAID-4, or RAID-6 with RAID-0 in the same way RAID-50 combines RAID-5 with RAID-0. These tend not to see use either due to obsolescence (in the case of RAID levels three and four) or cost-effectiveness. RAID-60, requiring two drives for parity in each RAID-6 sub-array, has excellent fault-tolerance but low capacity compared to other RAID arrays, and is more expensive to implement.
When RAID Fault Tolerance Isn’t Enough
If working for a data recovery lab teaches you anything, it’s that fault tolerance does not replace backup. Every data recovery lab in the world has seen plenty of RAID arrays that were fault-tolerant, but still failed due to everything from negligence and lack of proper oversight to natural disasters. “Fault tolerant” is not the same thing as “failure-proof”.
You can’t totally failure-proof your RAID array. But you can failure-proof your data by making sure it’s safely backed up. If your data is truly important to you, you’ll take the steps to make sure it’s well-protected, and keeping up-to-date backups can save your bacon when the worst happens.